Computer vision for brand-level logo detection of waste in real-time was tested. The brand recognition of waste items can be used to increase the granularity of the waste characterisation, simultaneously providing information to improve mass measurements. In the development of this technology, policy-makers can be provided the information necessary to develop Municipal Solid Waste (MSW) plans with a more refined spatial and temporal scale. Such information will facilitate identification of the sources of waste generation, the design of waste management facilities, predictions of material recovery potential, and the compliance with standards and regulations.
Brand-level Logo Detection for Product Identification
The algorithm was trained with three relevant brands:
1) Coca Cola; being the largest plastic polluter in Europe and the rest of the world.
2) Pepsi; the second largest plastic polluter in Europe and third in the world.
3) Heineken; the third biggest waste-polluting brand in Europe
Moreover, it was designed to perform logo detection only, discounting object segmentation.
Logo Detection (left) versus Logo Segmentation (right)
Code Architecture
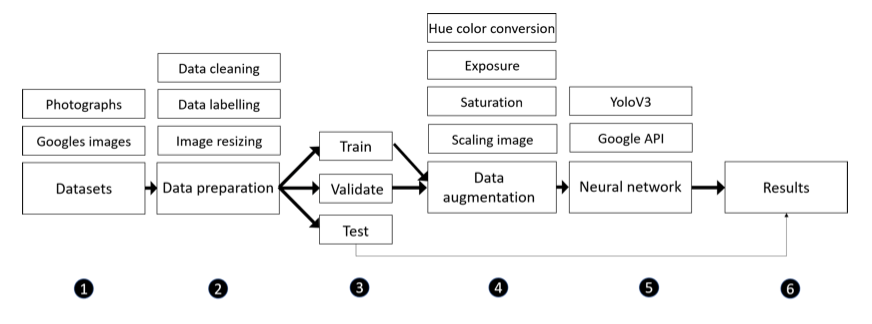
The structure of the algorithm used for brand-level logo detection
Datasets
The model has been trained using 1399 images from the internet. This provided the ability to see logos from various angles and shapes. A separate dataset was also created by capturing images of objects in various locations, which enabled greater detection accuracy by training the model using foreign environments with diverse conditions.
Data preparation
The first step involves removing images where the logo of the brand is not present on the image, as shown below.

Relevant image (left), irrelevant image (right)
Images are then labelled using an advanced software system that measures the bounding boxes surrounding each logo.
Train validation and test set
Datasets are generally split into training, validation, and test sets. The model is initially fitted on a training dataset in order to find parameters such as the weight in the neural network. The model is then used to predict responses in another dataset known as the validation dataset. This dataset provides an unbiased evaluation to fit hyperparameters such as the number of hidden units and also prevents overfitting. The model is then tested with a test dataset as it provides an unbiased evaluation of the model.
Data augmentation
The data augmentation used was provided by an external software, which included resizing, conversion to hue colour, and change in saturation and exposure.
Logo Detection Results

Examples of Coca Cola logo detection using bounding boxes

Examples of Pepsi logo detection using bounding boxes

Examples of Heineken logo detection using bounding boxes

Applications of the brand detector in industrial settings
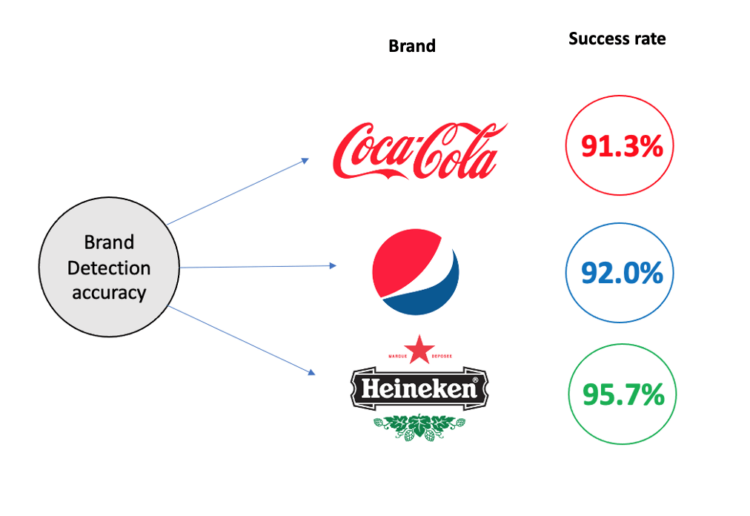
Brand Detection Accuracy (%)
The system proved to be resilient, being able to detect several logos simultaneously and from different brands. Logos that were upside down within the test set were also successfully identified, in addition to those that were con-mingled, deformed, and had different lighting conditions.
In Conclusion
An overall accuracy of 93% was obtained with varying lighting conditions, damaged and partially visible objects. With greater scope for improvement, this technology can be effectively implemented in industrial settings to support a closed-loop system of re-use that is necessary towards transitioning to the circular economy. Additionally, it provides a renewed extended producer responsibility (EPR) so that brands can take greater accountability for the environmental impacts of their product-end-life.